
Evaluating machine studying fashions past coaching information
Introduction
Lately, data-driven approaches equivalent to machine studying (ML) and deep studying (DL) have been utilized to a variety of duties together with machine translation and private personalized suggestions. These applied sciences reveal some patterns throughout the given coaching dataset by analyzing quite a few information. Nevertheless, if the given dataset has some biases and doesn’t embrace the information that you simply need to know or predict, it could be troublesome to get the right reply from the educated mannequin.
Let’s take into consideration the case of ChatGPT. The most recent model of ChatGPT right now is ChatGPT 4o, and this mannequin is educated on information till June 2023 (on the interval of this text). Subsequently, should you ask about one thing that occurred in 2024 not included within the coaching information, you’ll not get an correct reply. That is well-known as “hallucination,” and OpenAI added the preprocessing process to return a set reply as “unanswerable” for such sorts of questions. ChatGPT’s coaching information can be principally primarily based on paperwork written in English, so it’s not good at native area data outdoors of English-native nations equivalent to Japan and France. Subsequently, many corporations and analysis teams put a whole lot of effort into customizing their LLM by together with the area or domain-specific data utilizing RAG (Retrieval-Augmented Technology) or fine-tuning.
Therefore, figuring out what coaching information is used is essential for understanding the applicability and limitations of AI fashions. However, one of many greatest challenges in data-driven approaches is that these applied sciences typically have to carry out past the vary of the coaching dataset. These calls for are usually seen in new product improvement in materials science, predicting the results of recent pharmaceutical compounds, and predicting client conduct when launching merchandise within the markets. These situations require the right predictions within the sparse space and outdoors of the coaching information, which consult with interpolation and extrapolation.

Interpolation entails making predictions throughout the recognized information vary. If the coaching information is densely and uniformly distributed, correct predictions could be obtained inside that vary. Nevertheless, in apply, getting ready such information is unusual. However, extrapolation refers to creating predictions outdoors the recognized information factors’ vary. Though predictions in such areas are extremely desired, data-driven approaches usually battle probably the most. Consequently, it’s considerably essential to grasp the efficiency of each interpolation and extrapolation for every algorithm.

This text examines numerous machine studying algorithms for his or her interpolation and extrapolation capabilities. We put together a man-made coaching dataset and consider these capabilities by visualizing every mannequin’s prediction outcomes. The goal of machine studying algorithms are as follows:
- Symbolic Regressor
- SVR (Assist Vector Regression)
- Gaussian Course of Regressor (GPR)
- Resolution Tree Regressor
- Random Forest Regressor
- XGBoost
- LightGBM
As well as, we additionally consider ensemble fashions equivalent to Voting Regressor and Stacking Regressor.
Codes
Filled with codes can be found from beneath:
blog_TDS/02_compare_regression at main · rkiuchir/blog_TDS
Information Technology and Preprocessing
Firstly, we generate the substitute information utilizing a easy nonlinear perform that’s barely modified from the symbolic regressor’s tutorial in gplearn by including the exponential time period. This perform consists of linear, quadratic, and exponential phrases, outlined as follows:
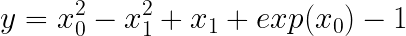
the place x₀ and x₁ take a variety of -1 to 1. The airplane of floor reality is as proven beneath:
https://medium.com/media/105af00e2d14c028ad531de4219abbe5/href
Since we study the efficiency of every ML mannequin when it comes to interpolation and extrapolation, completely different datasets might be wanted for every case.
For interpolation, we consider the mannequin efficiency throughout the similar vary as with the coaching dataset. Subsequently, every mannequin might be educated with discretized information factors throughout the vary of -1 to 1 and evaluated the anticipated floor throughout the similar vary.
However, for extrapolation, the aptitude of the mannequin throughout the vary outdoors of the coaching dataset might be required. We are going to prepare the mannequin utilizing the discretized information factors throughout the vary of -0.5 to 1 for each x₀ and x₁ and assess the anticipated floor throughout the vary of -1 to 1. Consequently, the distinction between the bottom reality and predicted floor within the vary of -1 to -0.5 for each x₀ and x₁ reveals the mannequin functionality when it comes to extrapolation.
On this article, the influence of the variety of factors for the coaching dataset might be evaluated by analyzing two instances: 20 and 100 factors.
For instance, 100 information factors are generated as follows:
import numpy as np
def target_function(x0, x1):
return x0**2 - x1**2 + x1 + np.exp(x0) - 1
# Generate coaching information for interpolation
X_train = rng.uniform(-1, 1, 200).reshape(100, 2)
y_train = target_function(X_train[:, 0], X_train[:, 1])
# Generate coaching information for extrapolation
X_train = rng.uniform(-0.5, 1, 200).reshape(100, 2)
y_train = target_function(X_train[:, 0], X_train[:, 1])
Introduction to Machine Studying Algorithms
On this article, we consider the efficiency of interpolation and extrapolation for the foremost 7 machine studying algorithms. As well as, the 6 ensemble fashions utilizing 7 algorithms are additionally thought of. Every algorithm has completely different constructions and points, that introduce execs and cons for predicting efficiency. Right here we summarize the traits of every algorithm as follows:
- Symbolic Regression
- A educated mannequin is expressed because the mathematical expressions fitted primarily based on the genetic algorithms
- Mannequin is outlined because the perform, contributing excessive interpretability
- Acceptable for the duty that focus on variable could be expressed as a perform of options
- Good at interpolation however could have some potential in extrapolation
Find Hidden Laws Within Your Data with Symbolic Regression
2. Assist Vector Regression (SVR)
- Primarily based on a Assist Vector Machine (SVM) that may effectively deal with the nonlinear relationship within the excessive dimensional areas utilizing the kernel technique
- Utilizing various kinds of kernels equivalent to linear, RBF, polynomial, and sigmoid kernels, a mannequin can categorical advanced information patterns
- Good at interpolation however much less steady in extrapolation
The Complete Guide to Support Vector Machine (SVM)
3. Gaussian Course of Regression (GPR)
- Primarily based on the Bayesian technique, the prediction is expressed because the likelihood which incorporates the anticipated worth and its uncertainty
- Because of the uncertainty estimation, GPR used for Bayesian Optimization
- Utilizing various kinds of kernels equivalent to linear, RBF, polynomial, and sigmoid kernels, a mannequin can categorical advanced information patterns
- Good at interpolation, and a few potential for extrapolation deciding on applicable kernel choice
Quick Start to Gaussian Process Regression
4. Resolution Tree
- Easy tree-shape algorithm which successively splits the information
- Straightforward to grasp and interpret however tends to overfit
- Step-like estimation for interpolation and never good at extrapolation
Decision Tree in Machine Learning
5. Random Forest
- An ensemble-based algorithm which is known as “Bagging” consisting of a number of resolution timber
- By combining a number of various timber, this algorithm can scale back overfitting danger and have a excessive interpolation efficiency
- Extra steady predictions than single resolution timber however not good at extrapolation
6. XGBoost
- An ensemble-based algorithm which is known as “Boosting” combines a number of resolution timber by sequentially decreasing errors
- Generally used for competitors equivalent to Kaggle due to the nice prediction efficiency
- Extra steady predictions than single resolution timber however not good at extrapolation
XGBoost: A Deep Dive into Boosting
7. LightGBM
- Much like XGBoost, however with sooner coaching velocity and reminiscence effectivity, which is extra appropriate for the bigger datasets
- Extra steady predictions than single resolution timber however not good at extrapolation
What is LightGBM, How to implement it? How to fine tune the parameters?
8. Voting Regressor
- An ensemble studying technique combining predictions from a number of fashions
- Mixing completely different mannequin traits, which contribute to extra strong predictions than a single mannequin
- Evaluated in three mixtures on this article:
– Assist Vector Regressor + Random Forest
– Gaussian Course of Regressor + Random Forest
– Random Forest + XGBoost
9. Stacking Regressor
- An ensemble studying technique that makes use of predictions from a number of fashions as enter for a ultimate prediction mannequin, “meta-model”
- Meta mannequin covers particular person mannequin weaknesses and combines every mannequin's strengths
- Evaluated in three mixtures on this article:
– Base mannequin: Assist Vector Regressor + Random Forest; Meta-model: Random Forest
– Base mannequin: Gaussian Course of Regressor + Random Forest; Meta-model: Random Forest
– Base mannequin: Random Forest + XGBoost; Meta-model: Random Forest
Utilizing these algorithms, we are going to consider each interpolation and extrapolation efficiency with the dataset we generated earlier. Within the following sections, the coaching strategies and analysis approaches for every mannequin might be defined.
Mannequin Coaching and Analysis
Preprocessing
Mainly, apart from tree-based approaches equivalent to Random Forest, XGBoost, and LightGBM, most machine studying algorithms require characteristic scaling. Nevertheless, since we solely use two options equivalent to x₀ and x₁ which take the identical vary, -1 to 1 (interpolation) or -0.5 to 1 (extrapolation) on this apply, we are going to skip the characteristic scaling.
Mannequin Coaching
For simplicity, parameter tuning just isn’t finished for all algorithms besides LightGBM of which default parameters are appropriate for the bigger dataset.
As launched within the earlier part, we are going to use completely different datasets for the analysis of interpolation and extrapolation throughout mannequin coaching.
Analysis and Visualization
After mannequin coaching, we are going to predict utilizing very finely discretized information. Primarily based on these predicted values, the prediction floor might be drawn utilizing the Plotly surface function.
These procedures are finished by the next code:
class ModelFitterAndVisualizer:
def __init__(self, X_train, y_train, y_truth, scaling=False, random_state=41):
"""
Initialize the ModelFitterAndVisualizer class with coaching and testing information.
Parameters:
X_train (pd.DataFrame): Coaching information options
y_train (pd.Sequence): Coaching information goal
y_truth (pd.Sequence): Floor reality for predictions
scaling (bool): Flag to point if scaling ought to be utilized
random_state (int): Seed for random quantity era
"""
self.X_train = X_train
self.y_train = y_train
self.y_truth = y_truth
self.initialize_models(random_state)
self.scaling = scaling
# Initialize fashions
# -----------------------------------------------------------------
def initialize_models(self, random_state):
"""
Initialize the fashions for use for becoming and prediction.
Parameters:
random_state (int): Seed for random quantity era
"""
# Outline kernel for GPR
kernel = 1.0 * RBF(length_scale=1.0) + WhiteKernel(noise_level=1.0)
# Outline Ensemble Fashions Estimator
# Resolution Tree + Kernel Technique
estimators_rf_svr = [
('rf', RandomForestRegressor(n_estimators=30, random_state=random_state)),
('svr', SVR(kernel='rbf')),
]
estimators_rf_gpr = [
('rf', RandomForestRegressor(n_estimators=30, random_state=random_state)),
('gpr', GaussianProcessRegressor(kernel=kernel, normalize_y=True, random_state=random_state))
]
# Resolution Timber
estimators_rf_xgb = [
('rf', RandomForestRegressor(n_estimators=30, random_state=random_state)),
('xgb', xgb.XGBRegressor(random_state=random_state)),
]
self.fashions = [
SymbolicRegressor(random_state=random_state),
SVR(kernel='rbf'),
GaussianProcessRegressor(kernel=kernel, normalize_y=True, random_state=random_state),
DecisionTreeRegressor(random_state=random_state),
RandomForestRegressor(random_state=random_state),
xgb.XGBRegressor(random_state=random_state),
lgbm.LGBMRegressor(n_estimators=50, num_leaves=10, min_child_samples=3, random_state=random_state),
VotingRegressor(estimators=estimators_rf_svr),
StackingRegressor(estimators=estimators_rf_svr,
final_estimator=RandomForestRegressor(random_state=random_state)),
VotingRegressor(estimators=estimators_rf_gpr),
StackingRegressor(estimators=estimators_rf_gpr,
final_estimator=RandomForestRegressor(random_state=random_state)),
VotingRegressor(estimators=estimators_rf_xgb),
StackingRegressor(estimators=estimators_rf_xgb,
final_estimator=RandomForestRegressor(random_state=random_state)),
]
# Outline graph titles
self.titles = [
"Ground Truth", "Training Points",
"SymbolicRegressor", "SVR", "GPR",
"DecisionTree", "RForest",
"XGBoost", "LGBM",
"Vote_rf_svr", "Stack_rf_svr__rf",
"Vote_rf_gpr", "Stack_rf_gpr__rf",
"Vote_rf_xgb", "Stack_rf_xgb__rf",
]
def fit_models(self):
"""
Match the fashions to the coaching information.
Returns:
self: Occasion of the category with fitted fashions
"""
if self.scaling:
scaler_X = MinMaxScaler()
self.X_train_scaled = scaler_X.fit_transform(self.X_train)
else:
self.X_train_scaled = self.X_train.copy()
for mannequin in self.fashions:
mannequin.match(self.X_train_scaled, self.y_train)
return self
def visualize_surface(self, x0, x1, width=400, peak=500,
num_panel_columns=5,
vertical_spacing=0.06, horizontal_spacing=0,
output=None, show=False, return_fig=False):
"""
Visualize the prediction floor for every mannequin.
Parameters:
x0 (np.ndarray): Meshgrid for characteristic 1
x1 (np.ndarray): Meshgrid for characteristic 2
width (int): Width of the plot
peak (int): Top of the plot
output (str): File path to save lots of the plot
show (bool): Flag to show the plot
"""
num_plots = len(self.fashions) + 2
num_panel_rows = num_plots // num_panel_columns
whole_width = width * num_panel_columns
whole_height = peak * num_panel_rows
specs = [[{'type': 'surface'} for _ in range(num_panel_columns)] for _ in vary(num_panel_rows)]
fig = make_subplots(rows=num_panel_rows, cols=num_panel_columns,
specs=specs, subplot_titles=self.titles,
vertical_spacing=vertical_spacing,
horizontal_spacing=horizontal_spacing)
for i, mannequin in enumerate([None, None] + self.fashions):
# Assign the subplot panels
row = i // num_panel_columns + 1
col = i % num_panel_columns + 1
# Plot coaching factors
if i == 1:
fig.add_trace(go.Scatter3d(x=self.X_train[:, 0], y=self.X_train[:, 1], z=self.y_train,
mode='markers', marker=dict(dimension=2, coloration='darkslategray'),
identify='Coaching Information'), row=row, col=col)
floor = go.Floor(z=self.y_truth, x=x0, y=x1,
showscale=False, opacity=.4)
fig.add_trace(floor, row=row, col=col)
# Plot predicted floor for every mannequin and floor reality
else:
y_pred = self.y_truth if mannequin is None else mannequin.predict(np.c_[x0.ravel(), x1.ravel()]).reshape(x0.form)
floor = go.Floor(z=y_pred, x=x0, y=x1,
showscale=False)
fig.add_trace(floor, row=row, col=col)
fig.update_scenes(dict(
xaxis_title='x0',
yaxis_title='x1',
zaxis_title='y',
), row=row, col=col)
fig.update_layout(title='Mannequin Predictions and Floor Fact',
width=whole_width,
peak=whole_height)
# Change digital camera angle
digital camera = dict(
up=dict(x=0, y=0, z=1),
heart=dict(x=0, y=0, z=0),
eye=dict(x=-1.25, y=-1.25, z=2)
)
for i in vary(num_plots):
fig.update_layout(**{f'scene{i+1}_camera': digital camera})
if show:
fig.present()
if output:
fig.write_html(output)
if return_fig:
return fig
Analysis of Interpolation Efficiency
The prediction surfaces for every algorithm are proven for coaching information instances of 100 and 20 factors respectively.
100 Coaching Factors:
https://medium.com/media/4241abc4ffc72cf162f2884328281783/href
20 Coaching Factors:
https://medium.com/media/bf38557f3a7b50dd97c8020a66fc7d90/href
Listed here are the summarized options for every algorithm:
Symbolic Regressor
This algorithm performs virtually completely in interpolation even with as few as 20 information factors. It’s because the Symbolic Regressor approximates the mathematical expressions and the straightforward practical kind is used on this apply. Because of this characteristic, the anticipated floor is notably clean which is completely different from the tree-based algorithms defined later.
Assist Vector Regressor (SVR), Gaussian Course of Regressor (GPR)
For kernel-based algorithms SVR and GPR, though the anticipated surfaces barely differ from the bottom reality, interpolation efficiency is usually good with 100 information factors. As well as, the prediction floor obtained from these fashions is clean just like one estimated by Symbolic Regressor. Nevertheless, within the case of 20 factors, there’s a important distinction between the anticipated floor and the bottom reality particularly for SVR.
Resolution Tree, Random Forest, XGBoost, LightGBM
Firstly, the prediction surfaces estimated by these 5 tree-based fashions are usually not clean however extra step-like shapes. This attribute arises from the construction and studying technique of resolution timber. Resolution timber break up the information recursively primarily based on a threshold for one of many options. Every information level is assigned to some leaf nodes whose values are represented as the typical worth of the information factors in that node. Subsequently, the prediction values are fixed inside every leaf node, leading to a step-like prediction floor.
The estimates of a single resolution tree clearly present this attribute. However, ensemble strategies like Random Forests, XGBoost, and LightGBM, which include many resolution timber inside a single mannequin, generate comparatively smoother prediction surfaces as a result of extra completely different thresholds primarily based on the numerous completely different shapes of resolution timber.
Voting Regressor, Stacking Regressor
The Voting Regressor combines the outcomes of two algorithms by averaging them. For mixtures like Random Forest + SVR, and Random Forest + GPR, the prediction surfaces mirror traits that blend the kernel-based and tree-based fashions. However, the mixture of tree-based fashions like Random Forest and XGBoost comparatively reduces the step-like form prediction floor than one estimated from the only mannequin.
The Stacking Regressor, which makes use of a meta-model to compute ultimate predictions primarily based on the outputs of a number of fashions, additionally exhibits step-like surfaces, due to the Random Forest used because the meta-model. This attribute might be modified if kernel-based algorithms like SVR or GPR are used because the meta-model.
Analysis of Extrapolation Efficiency
As defined earlier, every mannequin is educated with information starting from -0.5 to 1 for each x₀ and x₁ and people performances might be evaluated throughout the vary of -1 to 1. Subsequently, we get to know the extrapolation means to examine the prediction floor with the vary of -1 to -0.5 for each x₀ and x₁.
The prediction surfaces for every algorithm are proven for coaching information instances of 100 and 20 factors respectively.
100 Coaching Factors:
https://medium.com/media/8b3d0cf0435de5ca88be3468e5026dfe/href
20 Coaching Factors:
https://medium.com/media/998ac5c30752b2ff0102f1388804c5c2/href
Symbolic Regressor
The expected floor throughout the space of extrapolation obtained by the Symbolic Regressor which is educated with 100 information factors is nearly precisely estimated just like the interpolation analysis. Nevertheless, with solely 20 coaching information factors used, the anticipated floor differs from the bottom reality particularly within the fringe of the floor, indicating that the obtained practical kind just isn’t nicely estimated.
Assist Vector Regressor (SVR), Gaussian Course of Regressor (GPR)
Though each SVR and GPR are kernel-based algorithms, the obtained outcomes are completely completely different. For each of 20 and 100 information factors, whereas the anticipated floor from SVR is nicely not estimated, GPR predicts virtually completely even throughout the vary of extrapolation.
Resolution Tree, Random Forest, XGBoost, LightGBM
Though there are some variations among the many outcomes from these tree-based fashions, the anticipated surfaces are fixed within the vary of extrapolation. It’s because that call timber depend on splits and no splits are generated in extrapolation areas, which trigger fixed values.
Voting Regressor, Stacking Regressor
As seen above, the kernel-based algorithms have higher efficiency in comparison with the tree-based ones. The Voting Regressor with the mixture of Random Forest and XGBoost, and all three Stacking Regressors whose meta-model is Random Forest predict fixed within the vary of extrapolation. However, the prediction surfaces derived from the Voting Regressor with the mixture of Random Forest + SVR, and Random Forest + GPR have the blended traits of kernel-based and tree-based fashions.
Abstract
On this article, we evaluated the interpolation and extrapolation efficiency of the assorted machine studying algorithms. Because the floor reality information we used is expressed as a easy practical foam, symbolic regressor and kernel-based algorithms present a greater efficiency, particularly for extrapolation than tree-based algorithms. Nevertheless, extra advanced duties that can not be expressed in mathematical formulation would possibly carry completely different outcomes.
Thanks a lot for studying this text! I hope this text helps you perceive the interpolation and extrapolation efficiency of machine studying fashions, making it simpler to pick and apply the appropriate fashions on your initiatives.
Hyperlinks
Different articles
- How OpenAI’s Sora is Changing the Game: An Insight into Its Core Technologies
- Create “Interactive Globe + Earthquake Plot in Python
- Pandas Cheat Sheet for Data Preprocessing
Private web site
The Machine Learning Guide for Predictive Accuracy: Interpolation and Extrapolation was initially revealed in Towards Data Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.